
 英伟达真正难以被替代的,并不是GPU硬件本身,而是其背后长达十余年积累的 CUDA 软件生态。
英伟达真正难以被替代的,并不是GPU硬件本身,而是其背后长达十余年积累的 CUDA 软件生态。
如今,这一“软件护城河”正在被挑战。
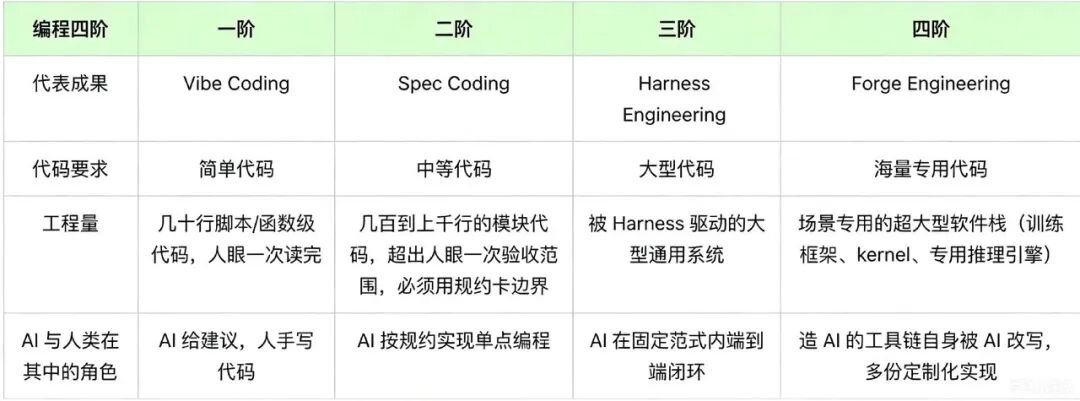
面壁智能正在尝试一件更激进的事:用 AI 直接重写 AI 的训练基础设施,让软件开发从“人类工程”变成“AI自动生成的工程体系”。
一、ForgeTrain:全球首个完全由 AI 编写的训练框架
近日,面壁智能发布了名为 ForgeTrain 的训练框架。
它的关键特点非常激进:
全球首个完全由 AI 编写、零人直接介入的生产级大模型训练框架。
该框架已经在华为昇腾系列芯片上完成 MiniCPM5-1B 的训练验证,并实现:
- 整体训练速度提升约 10%
- MiniCPM5-1B 预训练耗时约 3–5 天
- 在英伟达 GPU 上,MiniCPM4-0.5B 预训练约 2 天完成
更重要的是,这不是“实验代码”,而是已经跑通真实训练流程的生产级系统。
二、核心思路:让 AI “现场生成训练框架”
ForgeTrain 的本质,不是优化一个固定框架,而是改变软件生成方式。
面壁的核心假设是:
当大模型的 coding 能力足够强,软件开发成本趋近于零时,通用框架不再是最优解。
相反,更优路径可能是:
- 针对每个模型
- 针对每种芯片
- 针对每种训练任务
现场生成一套最优训练系统(on-demand framework)。
这也意味着,传统“通用训练框架时代”可能正在被改写。
三、AI写代码 + 人类设计Harness
ForgeTrain 的核心机制可以理解为:
AI负责写系统,人类负责设计“考场”。
这里的关键概念是 Harness(评测与约束系统)。
简单理解就是:
- 人类定义目标与约束
- 搭建评测环境(Harness)
- AI在闭环环境中不断生成代码并自我修正
整个过程类似一个自动化研发实验室:
- 从现有训练框架中提取关键指标,构建评测标准(Harness)
- AI基于这些标准生成“二进制一致”的训练框架
- 在约束中迭代优化,逐步提升性能并突破基准
目前 ForgeTrain 已经实现:
- 多机多卡训练框架生成
- 与 Megatron 结果一致
- 在部分场景下训练速度优于 Megatron 约 10%
四、从“人写代码”到“AI修系统”
在传统训练框架中,人类工程师需要:
- 写分布式训练逻辑
- 优化算子
- 管理显存与通信
- 调整并行策略
- 反复debug性能瓶颈
而在 ForgeTrain 模式中:
AI在闭环环境中自动生成代码,并通过评测系统自我修复错误。
人类的角色变成:
- 设计规则
- 定义约束
- 监督结果
甚至在部分内存优化场景中,AI生成的代码在合理约束下表现出更低显存占用。
五、关键突破:AI已经可以“写训练框架”
面壁团队表示,ForgeTrain 已经完成一个重要验证:
- 用它训练出的模型
- 与 Megatron 训练结果在人评和机评上保持一致
- 同时在性能上更优
这意味着它已经不是“代码生成实验”,而是:
可以稳定运行数天并完成完整模型训练的生产系统。
此外,该系统已经在 8B 模型上验证成功,并正在向 MoE 等更复杂模型扩展。
六、AI研发AI:下一代效率革命
过去几年,大模型进化主要依赖三件事:
- 数据规模
- 算力增长
- 资本投入
但现在,这条路径正在变得越来越昂贵:
- 高质量数据逐渐枯竭
- GPU与电力成本上升
- 规模扩展边际收益下降

因此,一个新方向正在出现:
用 AI 提升 AI 研发效率(AI for AI Research)
如果 AI 能参与以下环节:
- 代码生成
- 训练框架设计
- 算子优化
- 数据生成
- 实验迭代
- 模型架构探索
那么整个研发周期可能被压缩 10倍到100倍。
七、为什么“AI写AI”还没完全爆发?
问题并不是模型能力不够,而是:
AI研发系统本身缺少“可评测环境”。
在代码、数学、游戏等领域:
- 有编译器
- 有标准答案
- 有胜负机制
但在 AI 研发中:
- 没有统一评测标准
- 任务复杂且不稳定
- 成本极高
因此关键变成一句话:
能否把“AI研发”变成一个可评测系统?
这正是 Harness 的意义。
八、Harness:给AI造一个“考场”
Harness 本质是一个封闭系统,包括:
- 环境
- 工具链
- 任务流程
- 评分机制
AI在其中:
- 不断执行任务
- 根据反馈修正
- 持续迭代能力
ForgeTrain 正是在做一件事:
为“AI生成训练框架”这一任务建立专用考场。
一旦评测系统成立,AI就可以在其中不断进化。
九、软件工程范式正在改变:从通用框架到“现场锻造”
传统软件工程依赖大型通用框架,例如:
- Megatron
- DeepSpeed
- 各类统一训练系统
原因很简单:
人类写代码成本太高,所以必须“统一设计”。
但在 AI 编码成本趋近于零之后,这一逻辑正在失效:
未来可能变成:
- 一个模型 → 一套框架
- 一个芯片 → 一套优化系统
- 一个任务 → 一次现场生成的软件
这就是面壁提出的:
Forge Engineering(锻造式工程)
其核心思想是:
不再追求通用,而是追求“按需生成最优解”。
十、国产算力生态的另一条路径
一个更大的问题是:如何追赶英伟达生态?
英伟达的优势并不只是硬件,而是:
- CUDA生态
- 长期工程积累
- 海量开发者优化经验
传统方案(如TVM)试图用规则优化适配所有硬件,但现实问题是:
- 组合空间过大
- 性能难以最优
- 维护成本极高
而 AI 提供了一种新可能:
让AI成为“持续优化生态的开发者本身”。
面壁的目标是:
- 用 AI 重写训练框架
- 重写推理框架
- 重写算子系统
- 重写数据管线
最终实现:
当用户提出需求时,系统直接生成对应软件栈。
甚至团队提出一个目标:
到年底,重写一遍国产主流算力软件体系。
十一、未来方向:Human on the Loop
随着 AI 逐渐接管研发流程,人类角色正在变化:
- 过去:Human in the Loop(人参与执行)
- 现在:Human on the Loop(人监督系统)
未来研发可能变成:
- AI自主运行研发系统
- 人类只负责监控异常与调整方向
研发组织形态也可能随之改变。
十二、结语:软件工程正在进入“自动锻造时代”
ForgeTrain 的意义不只是一个训练框架,而是一个信号:
软件不再是“人写出来的”,而是“系统生成出来的”。
当 AI 可以:
- 写框架
- 优化算子
- 构建训练系统
- 自我评测与迭代
软件工程的本质就会发生改变:
从“工程师设计系统”,走向“系统自动生成系统”。
而 ForgeTrain,可能只是这个变化的起点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...