

5 月 28 日深夜,Anthropic 正式发布旗舰模型 Claude Opus 4.8。
相比 Opus 4.7,这次升级的重点,已经不只是传统意义上的“模型跑分”,而是开始明显转向开发者真实工作流。
Anthropic 这次最核心的更新,集中在两个方向:
- dynamic workflows
- 更便宜、更高速的 fast mode
前者,试图让 Claude 真正具备“大规模 agent 编排能力”;后者,则是在回应开发者越来越敏感的成本与吞吐问题。
而更值得注意的是——就在 Anthropic 高调展示 Opus 4.8 基准测试成绩的时候,Redis 作者 antirez 却公开质疑:这些跑分,真的代表真实编码体验吗?
与此同时,Ruby on Rails 作者 DHH 却在另一边疯狂称赞 GPT-5.5,甚至表示:
“自 Opus 4.5 之后,没有哪个模型像 GPT-5.5 一样,让我反复产生‘它居然已经强到这种程度了’的感觉。”
这场围绕“谁才是真正编码之王”的竞争,正在进入一个微妙阶段。
Opus 4.8 最大升级:让 Claude 开始“指挥 agents”
这次 Opus 4.8 最重要的新能力,是 dynamic workflows。
简单来说,它允许 Claude 自动编写 JavaScript workflow 脚本,再由运行时去调度大量 subagents 并行工作。
这意味着,Claude 不再只是一个“回答问题的聊天机器人”,而开始变成一个真正的任务调度系统。
在一次运行中:
- 最多支持 16 个 agents 并发
- 总 agents 数量上限达到 1000 个
Claude 会先拆解任务,再把不同子任务分配给不同 agents:
- 有的负责执行
- 有的负责验证
- 有的负责反驳结果
- 有的负责 review
整个过程会持续迭代,直到答案逐渐收敛。
更关键的是:
任务规划不再塞进上下文窗口,而是被转移到了 workflow 脚本里。中间结果保存在变量中,而不是疯狂消耗 context。
这实际上是在解决当前 AI agents 最大的问题之一:“上下文越来越长,任务却越来越不稳定。”
Anthropic 这次,本质上是在把 agent orchestration 从 Prompt Engineering,推进到 Runtime Engineering。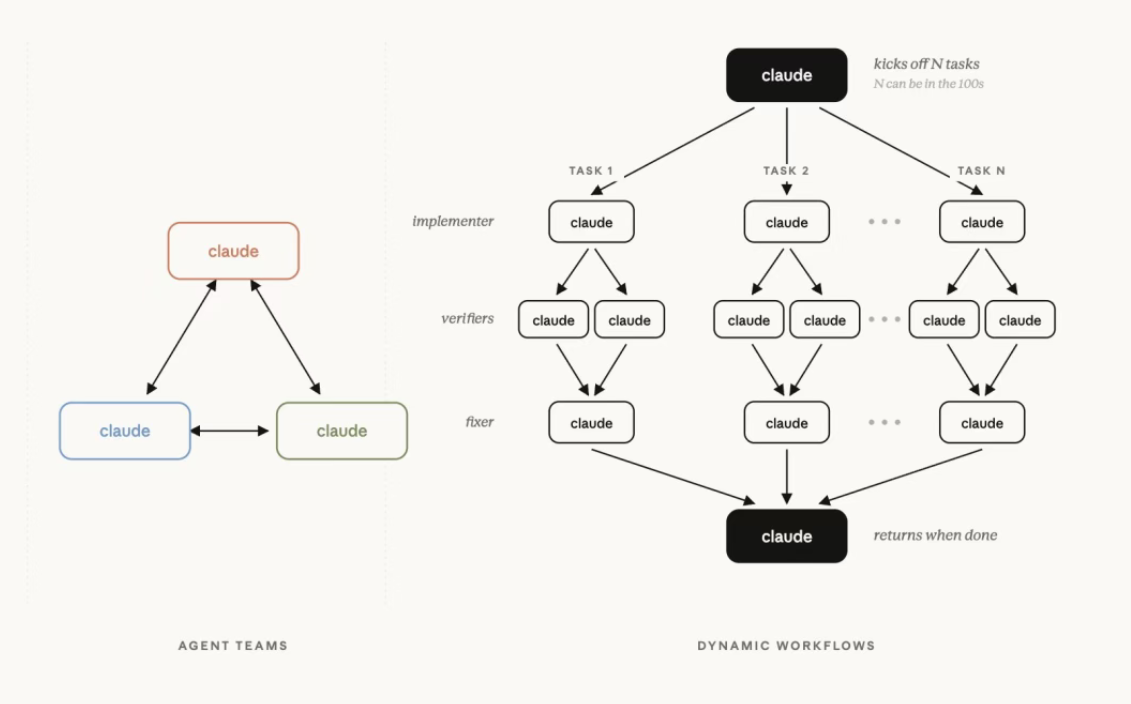
Claude 正在从“聊天 AI”,变成“后台操作系统”
Anthropic 还展示了一个非常激进的案例:Bun 团队使用 dynamic workflows,将 Bun 从 Zig 大规模迁移到 Rust。
整个过程:
- 生成约 75 万行 Rust 代码
- 通过 99.8% 测试套件
- 从第一次 commit 到 merge,仅用了 11 天
数百个 agents 并行工作。每个文件甚至还配备两个 reviewer agents。这已经不是简单的“AI 辅助编码”。
而是:
AI 开始接管软件工程流水线。从某种程度上说,Anthropic 想做的,已经不只是一个更强的模型,而是一个 AI 软件开发运行时。
新增“思考强度控制”:AI 开始出现“推理档位”
Opus 4.8 的第二个重点,是用户终于可以控制 Claude 的“思考强度”。
Anthropic 的逻辑很直接:
- 想要更强答案?
→ 增加推理资源 - 想要更快响应?
→ 降低思考深度
本质上,这相当于给模型增加了“性能模式”。
高强度模式下:
Claude 会更频繁、更深入地进行推理。
低强度模式下:
响应速度更快,同时额度消耗更慢。
对于现在越来越担心 AI “变相涨价”的用户来说,这个功能其实非常关键。
因为很多人已经明显感觉到:如今的大模型平台,正在通过“额度缩水”间接提高使用成本。
fast mode 降价:Anthropic 开始正面回应成本问题
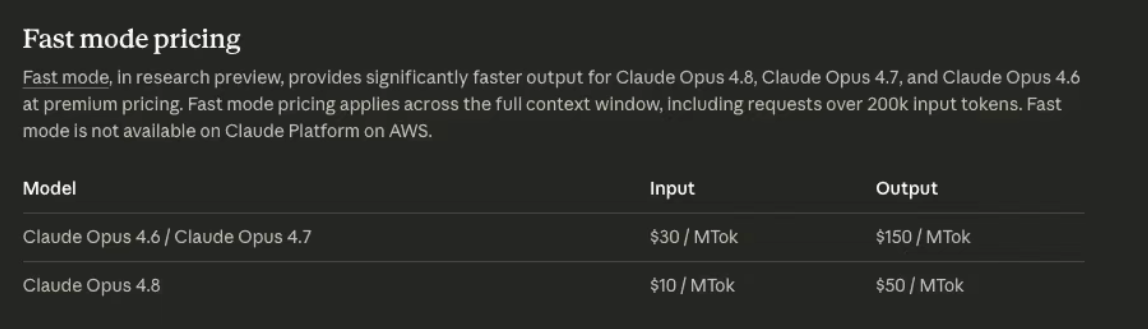
第三个重点,是 fast mode 大幅降价。
在 fast mode 下:
Opus 4.8 输出速度约为普通模式的 2.5 倍。而价格相比 Opus 4.7,直接下降了约三分之二。
新的价格:
- 输入:每百万 token 10 美元
- 输出:每百万 token 50 美元
这意味着 Anthropic 正在试图把 Opus 推向更真实的生产环境,而不仅
仅停留在“顶级模型展示”。
因为真正的大规模 agent 系统,最先撞上的问题,从来不是能力,而
是:吞吐、延迟与成本。
Anthropic 开始强调另一个关键词:“诚实”
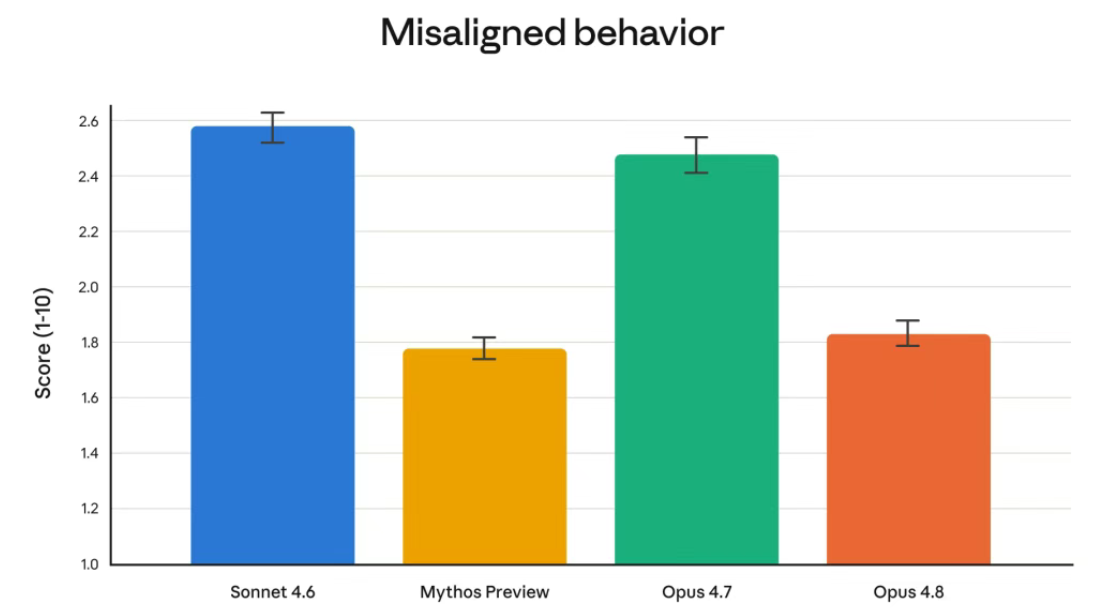
这次 Opus 4.8,还有一个非常耐人寻味的方向:Anthropic 正在越来越强调“模型诚实性”。
他们声称:
- Opus 4.8 更少欺骗用户
- 更少配合滥用请求
- 更愿意承认自己不知道
- 更容易指出代码中的潜在问题
Anthropic 甚至表示:相比前代模型,Opus 4.8 “忽略自身代码缺陷”的概率下降约 4 倍。
这其实反映了 AI 行业一个越来越现实的问题:模型变聪明,已经不够了。
真正稀缺的能力,开始变成:
- 是否可靠
- 是否稳定
- 是否会误导用户
- 是否敢于承认错误
过去,大家拼的是 IQ。现在,开始拼“可信度”。
但真正引爆争议的,是 Anthropic 的基准测试
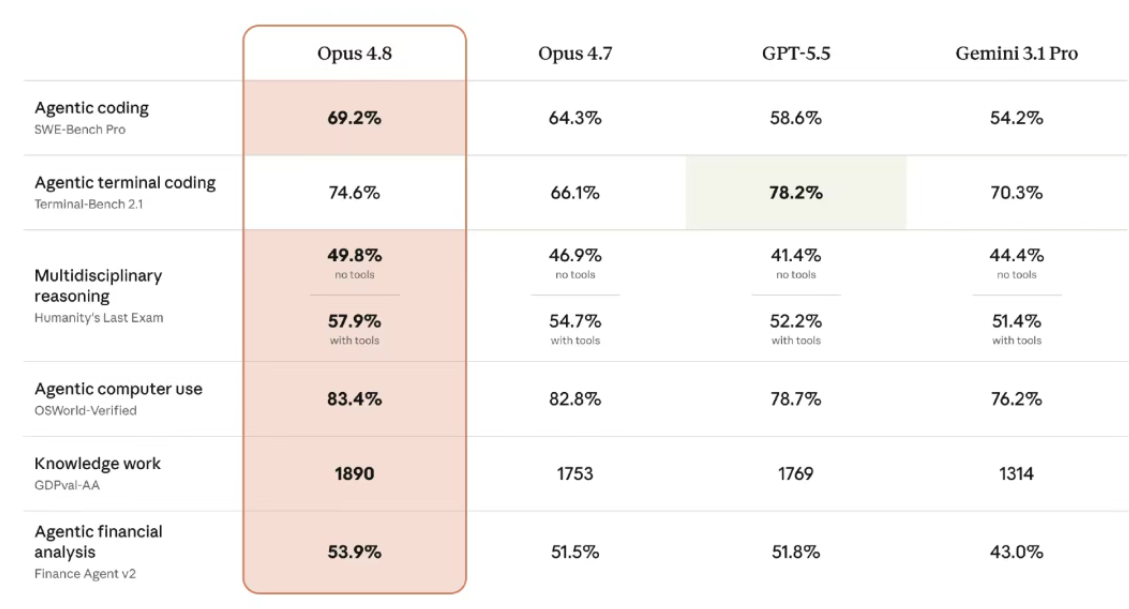
从官方跑分来看:Opus 4.8 在多个 agentic coding 基准中,已经超过 GPT-5.5 与 Gemini 3.1 Pro。
尤其在 agentic coding 项目中:
- Opus 4.8:69.2%
- GPT-5.5:58.65%
- Gemini 3.1 Pro:54.2%
 但问题在于:开发者社区的真实反馈,却并不完全一致。尤其最近,GPT-5.5 的编码口碑正在迅速升温。
但问题在于:开发者社区的真实反馈,却并不完全一致。尤其最近,GPT-5.5 的编码口碑正在迅速升温。
DHH 就公开表示:GPT-5.5 是近一年里,第一次让他持续产生“难以置信”感觉的模型。也正因如此,Redis 作者 antirez 直接批评 Anthropic:
“这是一个重大战略错误。”
因为:当大量开发者已经明显感受到 GPT-5.5 编码能力极强时,Anthropic 却依旧拿基准测试强调自己更强,反而会让用户开始怀疑:“跑分和真实体验,到底哪个更可信?”
这实际上暴露了 AI 行业如今最大的矛盾之一:Benchmark 正在逐渐失去对真实体验的解释力。
Anthropic:正在从“定义行业”,变成“追赶 OpenAI”?
不少开发者开始出现一种微妙感觉:Anthropic 似乎正在慢慢失去过去那种“定义节奏”的气场。
有用户评价:Opus 4.8 依然是一个非常强的模型。但现在的 Anthropic,更像是在追赶 OpenAI,而不是引领行业。尤其 GPT-5.5 出现之后,这种对比开始越来越明显。
因为 OpenAI 现在最可怕的地方,已经不只是 benchmark,而是:真实开发者体感。而 AI 行业历史已经反复证明:最终决定市场格局的,从来不是 PPT,也不是跑分。而是:开发者到底愿不愿意每天打开它。
Opus 这一年:从“编码封王”到“额度争议”
回看过去一年,Anthropic 对 Opus 系列的定位,其实一直非常明确:“世界最强编码模型。”
从 Opus 4,到 4.5,再到 4.6、4.7,Anthropic 一直在强调:
- agentic coding
- 长上下文
- computer use
- workflow automation
但与此同时,争议也越来越多:
- 长上下文价格暴涨
- 额度缩水
- 性能波动
- 模型稳定性下降
- 计费方式越来越复杂
很多开发者开始发现:模型能力确实越来越强。但使用体验,却未必越来越舒服。而 Opus 4.8,很明显正在试图修复这些问题。它不仅要证明:Claude 依然是顶级编码模型。
更要证明:Anthropic 仍然有能力继续参与下一轮 AI 平台战争。
结尾
Opus 4.8 的真正意义,可能不只是一次模型升级。它更像是 Anthropic 对未来 AI 方向的一次表态:下一阶段的大模型竞争,已经不只是“谁更聪明”。
而是谁能:
- 更稳定
- 更可靠
- 更低成本
- 更适合真实工作流
- 更像一个真正的软件系统
问题是:当 GPT-5.5 已经开始凭借真实编码体验动摇“编码王座”时,Anthropic 还能重新夺回定义行业节奏的话语权吗?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...