
根据报道,两名参与 Anthropic 项目的承包商表示,他们每完成一项创建提示词和审查代码的任务,可获得 280 美元报酬。每项任务通常耗时约一小时,但部分提交内容还需要与 Snorkel 的审核层进行多轮沟通。
根据 Business Insider 查阅到的 Snorkel 项目指南,参与 Marlin 项目的自由职业者需要对两个不同模型生成的代码进行 A/B 测试。他们会比较两组输出,选择自己更偏好的结果,并判断模型是否真正达到了提示词要求的细节程度。一名承包商称,该项目本质上是在训练 Claude Code 写出更简化、更易维护的代码。
从任务设计看,Marlin 更像是在模拟真实开发场景,而不是传统意义上的低门槛数据标注。承包商会从包含数千个代码仓库的列表中选择 GitHub 仓库,创建一个类似真实开发流程中的 PR,例如新增功能、修复漏洞或重构代码。随后,他们还需要编写提示词,说明希望模型完成什么任务。
在一项任务中,承包商要求模型重新组织系统存储和处理“执行元数据”(execution metadata)的方式。该任务的重点不是改变产品功能,而是在不影响实际运行逻辑的前提下,让代码结构更清晰、更方便开发者后续维护。
在另一项任务中,模型被要求完成一项安全修复,涉及开源机器学习平台 MLflow 在加载部分模型时下载 Python 软件包的方式。任务说明要求承包商从正确性、安全性、可靠性和可维护性角度评估代码,并确保修复方案既能阻止命令注入攻击,又不会误伤合法的白名单 pip 选项。
这意味着,Claude Code 的提升并不只是靠“写得更多”,而是靠专业工程师不断告诉模型:什么样的代码才算能进生产环境,什么样的修改只是表面可用,什么样的实现会在长期维护、安全边界和工程协作中留下隐患。据悉,目前 Marlin 项目仍在进行中,参与评估的承包商也并不知道自己正在测试的是哪个版本的模型。
值得注意的是,这也反映出了数据标注行业的结构性变化。过去,AI 数据工作往往被视为低门槛、重复性劳动;但随着模型能力提升,训练数据本身正在变得更加专业化。Snorkel 由斯坦福研究人员创办,公司会与拥有高等学位或同等经验的人合作,包括博士、医学博士和法学博士等,顶级专家每周收入可超过 3000 美元,其客户包括 Google、Mistral 和 Anthropic 等。除 Snorkel 外,Scale AI、Mercor 等平台也在为软件工程师提供最高每小时 110 美元的报酬。
Claude Code 正在被 Anthropic 推向更复杂的工程场景,但用户反馈也显示,这类 AI 编程工具距离稳定承担复杂工程任务仍有距离。
作为一个完全用 AI 写出来的编程工具,Claude Code 官方仓库里的用户反馈几乎每天都在刷新。近期就有用户称,自 2 月更新后,Claude Code 在复杂工程任务中的表现明显退化,已经“无法被信任用于复杂工程工作”。该 issue 已被关闭,但内容提供了一份非常详细的用户侧实测报告。
提交者称,Claude Code 会忽视指令、声称采用“最简单修复”,但结果错误、执行与要求相反的操作,并在没有真正完成任务的情况下宣称完成。
提交者表示,他们拥有一个高度稳定、复杂度较高的工程环境,并分析了从 1 月到 3 月的大量 Claude Code 会话日志。报告称,对 6852 个 Claude Code 会话文件、17871 个 thinking blocks 以及 234760 次工具调用的定量分析显示,所谓“thinking content redaction”的推出,与复杂、长会话工程工作流中的质量退化高度相关。其认为,当模型的思考深度下降时,它的工作模式会从“先研究、再修改”转向“先编辑、少研究”,进而导致多步骤研究、项目约定遵循、谨慎代码修改等能力下降。
数据显示,Claude Code 在修改代码前的阅读行为明显减少。在表现较好的阶段,模型每次编辑前平均有 6.6 次文件读取;而在退化阶段,这一数据降至 2.0,相当于修改前研究量减少约 70%。这让模型更容易做出“没读就改”的操作。该用户认为,这会导致模型破坏周边代码、违反文件级约定、把新代码插入注释块中间,或者重复实现文件中已经存在的逻辑。
除了代码修改方式变粗糙,用户还记录了更多行为层面的异常。例如,模型出现更多推理循环,输出中频繁出现“等等”“实际上”“让我重新考虑”等自我修正;“simplest”一类表达出现频率上升,被用户解读为模型开始倾向于选择最低成本方案,而不是正确方案;模型也更容易提前停止、请求许可,或者把问题归因于“已有问题”“已知限制”。
这种质量下降的反馈并不是偶然。4 月,一位自称过去四个月几乎每天大量使用 Claude Code 的用户表示,近期体验明显变差。过去,处理网站、落地页等任务时,Claude Code 可以产出不错结果;现在则经常需要反复解释需求,甚至在模型开始执行明显错误的方向时,不得不立刻中止。
该用户提到,Claude Code 频繁出现“做错后道歉”的情况,而自己的提示词、工作类型和使用方式并没有变化。后来问题严重到,他在用 Claude Code 构建内容后,还需要转向 Codex 对其结果进行事实核查。 此外,Claude Code 还出现了忘记一些基础工作流程、执行任务时突然停止等问题。
这反映了 Claude Code 乃至整个 AI 编程工具的关键矛盾:越深入复杂工程场景,就越不能只追求“快”和“会改代码”,而必须具备长期上下文理解、工程约定遵循、多文件推理等。要知道,开发者对工作流级别的可靠性下降是很敏感的。
因此,Anthropic 引入约 1000 名人类软件工程师,实际上是在用专业工程实践为 Claude Code 补课,用资深开发者的判断标准来弥补当前能力的不足。
颇具讽刺意味的一点是,从“vibe coding”走向“工程化 coding”过程中,我们越想让 AI 像高级软件工程师一样工作,似乎就越需要大量真正的软件工程师参与训练。
去年 3 月,Anthropic CEO Dario Amodei 曾预测,未来 3—6 个月,AI 可能写出 90% 的代码;12 个月后,AI 甚至可能几乎写出全部代码。这也是 Anthropic 发力编程的很大现实动力。
有段时间,“AI 代码占比”一度成为科技公司展示 AI 化程度的新指标。谷歌是最典型的案例。2024 年第三季度财报电话会上,谷歌 CEO Sundar Pichai 表示,公司超过四分之一的新代码由 AI 生成,随后再由工程师审查和接受。而到了今年 4 月,Pichai 又表示,谷歌 75% 的新代码已经由 AI 生成。
相比大公司,创业公司对 AI 编程的接受程度更激进。此前有报道称,YC 管理合伙人 Jared Friedman 表示,在 W25 批次中,约四分之一创业公司的代码库有 95% 由 AI 生成。这在当时还引发了大量开发者质疑。
而 Anthropic 在今天发布文章《When AI builds itself》指出,在 AI 发展史上,模型研发过去主要由人类驱动;但在 Anthropic 内部,越来越多 AI 开发工作已经交给 AI 系统完成,这正在显著加快公司的研发速度。根据其披露的数据,截至 2026 年 5 月,Anthropic 合并进生产代码库的代码中,超过 80% 由 Claude 编写;而在 Claude Code 于 2025 年 2 月发布研究预览版之前,这一比例还只是个位数。
此外,截至 2026 年第二季度,其典型工程师每天合并的代码量已经达到 2024 年的 8 倍。 不过,Anthropic 承认,代码行数并不是完美的生产力指标,因为它更强调数量而非质量。因此,“8 倍代码量”很可能高估了真实生产力提升。但 Anthropic 认为,这至少证明了内部研发速度正在显著加快。
无论如何,在 Claude Code、Codex 等工具推动下,AI 编程工具已经席卷海内外。而随着 AI 代码越来越多,如何做好 AI 代码治理则成为社区的头等大事。对此,认为 AI 已经接近人类水平的 Anthropic,并没有提及过相关信息,仅仅是在博文中呼吁建立可验证的减速或暂停机制。
现在,开源社区在各自探索对 AI 代码的处理方式。有些社区做法比较简单:开源编程语言 Zig 明确禁止提交 AI 辅助生成的代码,包括大模型生成的内容和大模型改写、编辑、构思或调试过的内容。简单来说,就是不要把 AI 带进来。Zig 总裁 Andrew Kelley 将 AI 辅助贡献称为“基本都是垃圾”。“有人给我们发来的贡献没有任何价值。它们甚至是负价值,因为它们占用了团队的代码审查时间。”在 Kelley 看来,这些 AI 编程者更像是“路过式贡献者”:他们可能会提交一两个 pull request,但永远不会真正加入核心团队。他表示,如果他说只接受“好的”AI PR,那么审查者就必须逐一判断每个提交是否合格。“但如果我说一律不接受,那这个政策就非常容易执行。”虽然 Zig 规模相对较小,但它已经产生了超出体量的影响。例如,Bun 就是用 Zig 创建的,而 Bun 后来被 Anthropic 收购。Zig 的 AI 禁令随后也在 Bun 与 Zig 之间引发了一些争议。
Kelley 表示,对 Zig 来说,“导师制”本身就是项目核心使命的一部分,因此 AI 生成的贡献反而会适得其反。“我们都在努力让自己成为更好的程序员。那些发送 AI PR 的人,并不会帮助实现这个目标。”另一方面,Linux 社区则已经开始探索 AI 工具如何更加规范。此前官方发布的《AI Coding Assistants》指导文件,给 AI 参与严肃开源基础设施开发提供了一套清晰边界。文件明确,AI 工具可以辅助 Linux 内核开发,但相关贡献必须严格遵守内核现有开发流程、许可证要求和补丁提交规范。根据文档,所有使用 AI 辅助提交到 Linux 内核的代码,仍然必须遵循标准内核开发流程,包括内核开发流程指南、Linux 内核编码风格,以及补丁提交规范。在许可证方面,文档明确要求,所有贡献都必须符合 Linux 内核的许可规则,即代码必须与 GPL-2.0-only 兼容,并使用合适的 SPDX 许可证标识。
最关键的规定出现在 Signed-off-by 和 DCO 部分。Linux 内核文档明确写道,AI agent 不得添加 Signed-off-by 标签。原因是,只有人类才能在法律意义上认证 Developer Certificate of Origin,也就是 DCO。人类提交者必须审查所有 AI 生成代码,确保其符合许可要求,并添加自己的 Signed-off-by 标签,对贡献承担全部责任。
这条规定直接划清了 AI 编程助手在开源贡献中的责任边界:AI 可以写代码、改代码、辅助分析,但不能成为法律责任主体。真正提交补丁的人类开发者,仍然是代码来源、许可证合规、质量和后续维护责任的承担者。
文档同时要求,当 AI 工具参与内核开发时,应当通过 Assisted-by 标签进行归因,以便追踪 AI 在开发流程中的作用。推荐格式为:
Assisted-by: AGENT_NAME:MODEL_VERSION其中,AGENT_NAME 指 AI 工具或框架名称,MODEL_VERSION 指具体模型版本,后面可以列出使用过的专业分析工具,例如 coccinelle、sparse、smatch、clang-tidy 等。但 git、gcc、make、编辑器等基础开发工具不需要列入。文档给出的示例是:
Assisted-by: Claude:claude-3-opus coccinelle sparse可以看出,相比直接拒绝 AI 辅助贡献,Linux 采取的是更工程化的治理方式:允许使用,但必须透明披露;可以辅助,但不能签署;可以生成代码,但人类必须 review、作证并承担责任。在 AI 编程野蛮生长一段时间后,现在人类工程师依然重要。
除了开源社区,大厂也在探索如何把 AI 放进软件交付流程。Cloudflare 在今年 4 月 20 日发布博客披露,公司已在内部 CI/CD 流程中部署一套 AI 代码审查系统。工程师提交 merge request 后,系统会自动启动七个专门化 AI reviewer,对代码进行初步审查,并根据风险等级决定批准、评论或阻止合并。Cloudflare 称,该系统已内部运行约一个月,覆盖 5169 个代码仓库,完成 131246 次审查,涉及 48095 个 merge request。平均每个 MR 被审查 2.7 次,审查完成时间中位数为 3 分 39 秒。平均每次审查成本为 1.19 美元,P99 成本为 4.45 美元。
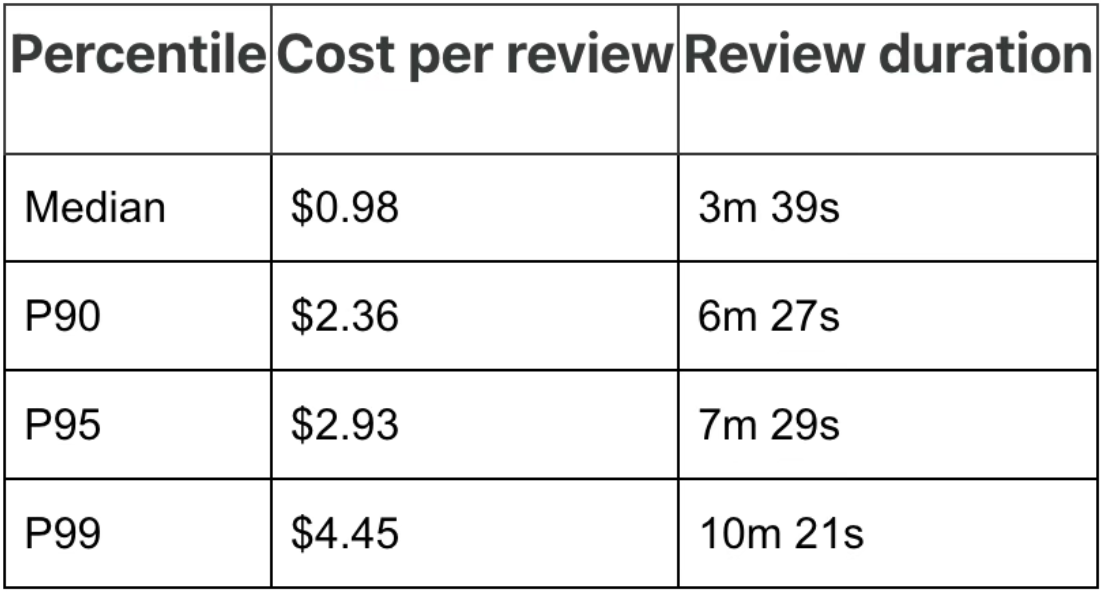
Cloudflare 在博客里提到,有效的 AI 审查不仅要告诉模型“看什么”,更要明确告诉它“不要看什么”。例如,安全 reviewer 只标记可利用或具体危险的问题,如注入漏洞、认证 / 授权绕过、硬编码密钥、不安全加密用法、缺失输入验证等;但不标记理论风险、无关旧代码问题或泛泛的“建议使用某个库”。
Cloudflare 为 AI 审查结果设置了明确决策规则:如果没有问题或只有轻微建议,系统会批准;如果存在警告(Warning)但没有生产风险,可以带评论批准;如果多个警告交织形成风险模式,系统会撤销机器人批准;如果出现严重(Critical)问题或生产安全风险,系统会 提出修改请求(Request changes),从而阻止合并。
但是,Cloudflare 也保留了人工“break glass”通道。人类 reviewer 可以通过评论 break glass 强制批准,用于紧急 hotfix 或避免被模型服务故障卡住发布。系统会在 telemetry 中记录这类覆盖行为。Cloudflare 明确表示,这套 AI code review 系统还不能替代人类 reviewer。AI 在架构判断、跨系统影响、复杂并发问题和大型重构方面仍有明显限制。
例如,AI 能看到 diff 和周边代码,但不一定理解系统为什么这样设计;它可以发现 API 合约变化,却无法确认所有下游消费者是否已更新;它能看到缺少锁,但未必能推断完整死锁路径。
因此,Cloudflare 对 AI 代码审查的定位不是取代人类,而是自动化第一轮、重复性、跨领域的初筛:让 AI 先发现明显 bug、安全风险、性能问题、文档遗漏和内部规范冲突,再由人类处理更复杂的架构判断和责任决策。
不过,值得注意的是,Anthropic 认为,随着人类代码和 AI 代码质量趋近,人类可能会逐渐停止亲手写代码,转向主要审查 AI 写出的代码。但如果人类无法像 Claude 生成代码那样快速审查代码,人类 review 就会成为 AI 研发的新瓶颈。
另外,为控制成本,Cloudflare 将 MR 分为 trivial、lite 和 full 三档。trivial 适用于 10 行以内、文件数不超过 20 个的小改动;lite 适用于 100 行以内、文件数不超过 20 个的改动;full 则适用于超过 100 行、超过 50 个文件,或涉及安全敏感路径的改动。任何触及 auth/、crypto/ 或安全相关文件的改动,都会触发 full review。
模型选择也按任务复杂度分层:Claude Opus 4.7 和 GPT-5.4 主要用于最复杂的 coordinator;Claude Sonnet 4.6 和 GPT-5.3 Codex 用于代码质量、安全、性能等重型 reviewer;Kimi K2.5 用于文档、发布、AGENTS.md 等偏文本和轻量任务。
一个月内,这套系统处理了约 1200 亿 token,其中大部分是 cache reads。Cloudflare 称,系统缓存命中率达到 85.7%,相比按完整输入 token 计价,节省了估计五位数美元成本。
从 Cloudflare 的实践可以看出,对于 AI 编程工具,具备更可靠、生产级标准的工程能力,会成为下一阶段的重要竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...